简介
Spark Sql,用于sql与结构化数据处理MLlib,用于机器学习GraphX,图处理Spark Streaming,流处理
架构
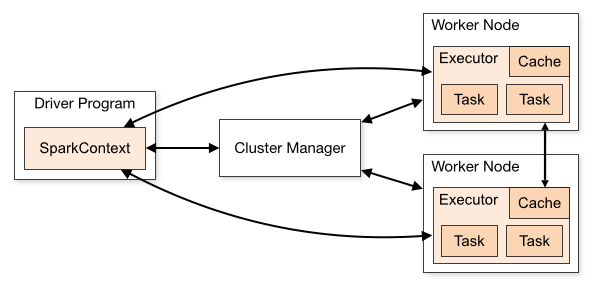
SparkContext源码解析可以连接不同集群管理器(standalone,mesos,yarn).一旦连接上,spark会申请集群node上的executor来执行计算、存储数据。然后,发送代码(defined by jar or python files to SparkContext)到executor。最后,sparkContext发送tasks给executors执行
名词解释
| Term | Meaning |
|---|---|
| Driver program | The process running the main() function of the application and creating the SparkContext |
| Deploy mode | Distinguishes where the driver process runs. In “cluster” mode, the framework launches the driver inside of the cluster. In “client” mode, the submitter launches the driver outside of the cluster. |
| Executor | A process launched for an application on a worker node, that runs tasks and keeps data in memory or disk storage across them. Each application has its own executors. |
| Stage | Each job gets divided into smaller sets of tasks called stages that depend on each other (similar to the map and reduce stages in MapReduce); you’ll see this term used in the driver’s logs. |
| Job | A parallel computation consisting of multiple tasks that gets spawned in response to a Spark action (e.g. save, collect); you’ll see this term used in the driver’s logs. |
配置 HistoryServer
spark web ui 4040端口在spark跑完后会关掉,配置spark的HistoryServer功能
配置 $SPARK_HOME/conf/spark-defaults.conf1
2
3
4spark.eventLog.enabled true
spark.eventLog.dir hdfs://localhost:9000/spark_log
spark.eventLog.compress true
spark.history.fs.logDirectory hdfs://localhost:9000/spark_log
$SPARK_HOME/conf/spark-env.sh1
xport SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=10000 -Dspark.history.fs.logDirectory=hdfs://localhost:9000/spark_log"
在hdfs创建log目录1
HADOOP_HOME/bin/hdfs dfs -mkdir /spark_log
1 | bin/spark-submit --master spark://localhost:7077 --jars /opt/spark/examples/jars/spark-examples_2.11-2.3.1.jar --class org.apache.spark.examples.GroupByTest 2 1000 1000 2 |
通过spark-submit 提交的application会在http://spark-master:18080/展示
参考: